As a general rule, we humans don’t have to think much if at all about our depth perception. We often take for granted that if we reach for something, it is in that general vicinity, if we take a step down, the ground is about where we expect it to be, and so on.
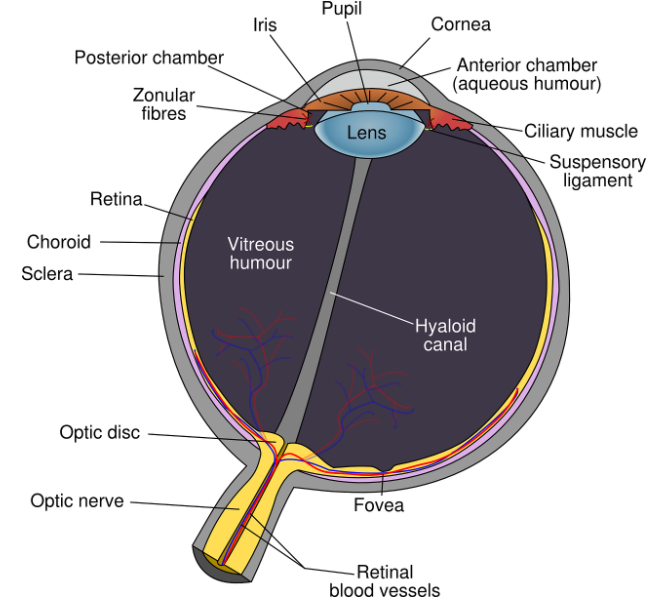
If you know anything about how the brain works or if you’ve been paying attention at your last eye appointment, you may know that the way our vision works is by receiving light in our eyes which then gets reflected and reformatted (backward and upside down) as an image in the brain.
But did you know that these images recorded through our retinas only have the capability to be represented in 2D?
That’s right! The retinas’ detailed re-picturing occurs as a fully two-dimensional process, including length and width, but lacking depth.
How then is it possible for us to perceive distance with relative accuracy? How is it that the brain manages this feat without the ability to perceive in all three dimensions?
In fact, experiments on cross-eyed and wall-eyed cats revealed that when these animals did not develop corrective vision, they would most likely lack stereovision, or the ability to perceive depth and see in 3D.
Clearly, it is up to the eyes and their proper alignment to create the perception of 3D objects and distances in the real world, but retinas only reflect their imagery onto the brain in 2D. What gives?

The Lovely Cooperative
Even though the phenomena of 3D vision has yet to be fully explained, science has come close.
Scientists from the University of York explain most mammals have two eyes for a reason. And each one of these eyes plays its own role in surmising a complete view of the world around us.
In essence, the researchers relate the various positions of the two eyes to the creation of two different ‘pathways’. Each eye differs by degrees in relation to the other and it is this difference that allows it to create the picture of relative depth.
Of course, it’s not quite this simple. Not only are the different pathways responsible for imaging at various angles, but they also process the images at different speeds.
One eye signals at a slow speed while the other signals much quicker, and these signals are actually sent along two separate neuropathways in the brain. It is in this way that we make distinctions that allow us to perform tasks whether objects in question are stationary or in motion.
This occurrence is also responsible for the fact that people with lazy eye syndrome tend to struggle with depth perception and 3D vision in general, but there is no similar disparity relative to objects in motion. The eyes process motion, depth, and color, and depth and motion send signals through different routes from the eyes to the processing center in the brain.
The need to perceive 3D objects at two separate but constant angles in order to render multiple 2D images with “fake” or extrapolated depth makes 3D vision difficult for a number of people with various eye weaknesses or disparities. The more that can be learned about the way 3D vision works in humans, the more likely science will be able to help remedy these differences in development.
One man taught himself to see in 3D by experimenting with his own innately crossed eyes, one separate from the other, but these results are currently quite uncommon.
A Lesson from Art
Stereoscopic vision through this so-called trick of rendering depth only works well at distances of less than 20 feet. After this point, the brain must use relativity “tricks” based on the light-refraction, color-filtering, and light polarization.
This is to say perspectives, shades, and shadows become much more important in rendering the relative depths of objects nearer and farther. Much like the way a 2D drawing or portrait must have proper shading to create the appearance of depth when the angles needed for stereoscopic vision aren’t readily available, the brain processes the light variances taken in from the eyes as relative distance and depths.
Imagine for a moment the eye placement on a tiger versus a rabbit. The tiger, a predator, has a stereoscopic vision similar to a human. They have eyes close enough together where the same object can be viewed at two slightly different angles and create a relatively accurate representation of the depth of view. This is, of course, highly important should the tiger want to, for example, pounce on something with precision.
Rabbits on the other hand have each eye placed very opposite one another, on completely different sides of their faces. For the rabbit, it is much more important to have as wide a field a view as possible, to see as much of the environment at once. They much more readily depend on shading, textures, and shadows like a painting to create a less accurate distance, but a highly relative perception of depth in 3D. With rabbits being as quick as they are, that little bit of difference holds little weight in a full sprint away from a predator.
Patterns in the Visual Cortex
Human perception attempts to take the best of both worlds.
Functional magnetic resonance imaging (fMRI) research at the Ohio State University attempted to further our understanding of the multiple pathways signals take when 3D imagery is being rendered.
By having volunteers view images with 3D glasses, they were able to see in real-time what was happening in the brains of the participants as they viewed and reviewed the fMRI scans.
While the brain was looking at three-dimensional images, they saw the image first create activity along the visual cortex, where the majority of the two-dimensional information rendering occurs. As the process continued, however, the brain activity showed different signs as the emphasis moved to figure out exact and relative depths.
In this way, it seemed as if the fully 3D pictures that we instantly see and take for granted actually start off as fully flat, 2D renditions, and the depth dimension is gradually added to this existing basis.
Depth information is inferred by the “binocular disparity” we spoke of early, the result of two eyes viewing an image at different angles, but in addition to this, it takes extra time for the depth to be added as a separate factor.
The fMRI technique allowed the scientists to compare brain activity patterns in the cortex per the image being viewed by the participant. It was noted that for images in only 2D, with no depth aspect patterns occurred in the early visual cortex, but images in 3D created activity in later areas of the cortex.
Soon, the researchers hope to be able to actually quantify this data and create models based on the 3D representations of perceived items in the brain.

The Pathways of the Cortex
Recent research now suggests different parts of the visual cortex trace different computations along the dorsal and ventral pathways. The human brain includes two pathways for processing visuals – the ventral and the dorsal.
The dorsal pathway is known to be more involved in spatial-, attention-, and action-based processing, while the ventral pathway is all about object recognition.
Together these two pathways create a constant stream of visual processing for the waking mind.
The spatiality-relations of the dorsal visual pathway make it the processing center for the “depth-addition” processes, whether that is through the binocular disparity of the streams between the two eyes or in relation to shades and shadows. This is likely to be a 3D added representation noticed by the fMRI patterns of the later visual cortex.
The initial renderings and activity patterns of the early visual cortex are likely created by the ventral visual pathway, making it possible to create representations in the brain of the initial images in question with regard to things like shape and color.
With the dorsal visual cortex being highly engaged by its processing of information for depth, it is also involved in integrating representation signals for the recreation of the structure of viewed surfaces. The ventral cortex may store representations of object configurations and the features required for task performance.

Hope for Future Development
There is still a long way to go to fully understand the specifics of 3D rendering in the brain. Even though research has enlightened us a lot to the general workings of the visual transformation from 2D images received by the retinas to something comprehensible as three-dimensioned, with depth that we can perceive with relatively consistent accuracy, there is much work to be done before these findings can become useful beyond the exploratory and explanatory fashion.
If we want to be able to fix the disparities when there is difficulty in perceiving depth or rending 3D imagery in humans, more quantitative work will be necessary to have an exact understanding. Strangely, it is not as simple as corrective surgery, proving that science still has a ways to go.
One recent development, however, just may cut the research time dramatically when it comes to fully understanding this capability, freeing the focus to find solutions.
Researchers have actually managed to create artificial intelligence that replicates human vision.
Deep, multilayer networks have made AI object recognition possible at high capacity for gaming and training purposes, but this only mimics the ventral pathway for the 2D imagery of the visual cortex.
These AI networks were developed based on the multi-stage visual pathways in the human brain, as they realized the ability to recreate and closely observe similarities and correlations between natural and artificial intelligence could prove highly useful.
The researchers, however, were not expecting the AI’s evolution and lifetime learning to begin to integrate 3D patterning as well. AlexNet, the AI in question, showed remarkably similar responses to testing across natural and artificial intelligence, when it was only trained to label photos of 2D objects.
This, of course, is correlated to the dorsal pathway in humans, as the spatial recognition center responsible for converting 2D into 3D images, but simply programming the AI to respond with similar activity patterns in the brain as humans led the AI to be capable of rendering and recognizing 3D imagery as well.
The ability to represent 3D shape fragments and detect 3D shapes aids in the interpretation of the real world, and it seems merely the correlation between the 3D imaging capacity in humans, as patterns and pathways, was enough to mimic the real thing, leading researchers to further question the deep integration between the 2D image rendering by the retinas into the 3D perception with a depth we expect.
A Process We Don’t Have to Think About
So that’s how the brain works. This seemingly simple process of seeing in 3D is actually quite the complicated series of processes, systems, pathways, and renderings all brought together in a fraction of a second.
Through the use of binocular disparity, the placement of our eyes on our face makes it possible to “artificially” render the third dimension, depth, in the representations we process in our minds.
Not only that, but the process itself is linear, not everything occurs at once, instead, one part of the brain, the ventral pathway, takes in the 2D images, and another part, the dorsal pathway adds in spatial recognition after the fact.
This partially explains the complications inherent to eye complications such as lazy eyes syndrome, crossed eyes, and walled eyes, however, this knowledge is just the tip of the iceberg relative to research to fix and remedy these things.
On that note, humans have a long way to go, but with the help of artificial intelligence, we just may shrink the timeline. Of course, research is progressing all the time, and as it turns out, AI just may surprise us and test the limit!
Return to Blog Home